Overview
I generally prefer to try and predict future success for players or teams. Who will be good or bad, what was a good move or bad, etc. But I had a bunch of data, and I always play a mock draft game with some friends where we try to predict the first round of the draft correctly. This is usually not something that I would try to model, because so much of it is vibes, and leaks/rumors in the last few days. I figured I could throw something together to try and predict it based on what teams have done in the past and just see how it turned out.
I had a few characteristics/stats that I wanted to look at for this: scoring, position, height/weight, nationality, league, and "reach-ness". Scoring is simple, and self explanatory, at each pick, do teams take high scoring guys or low scoring guys relative to who's left. AKA who comes out on top/bottom of NHLe model's grades all the time (CAR vs OTT). Position was another one, is there a team that always takes Fs in the first, or never drafts a G. This was a bit more iffy on usefulness because if teams have always drafted Fs high, they should hopefully have a good group of Fs and now need a D. Height and weight is another obvious one, some teams are far more willing to take a chance on the small skilled player, while others almost always go with the beeg bois. Like MTL with Mooney this year, Hutson a few years ago, or Arizona/Utah with Samu Bau, Daniil But, Dmitri Simashev, etc. Similarly with nationality and league, some teams just never draft Russians (PIT, ANA) or players out of Russian leagues, or others love their Swedes (DET). So I didn't want the model to predict the pens taking Zharavsky or something like that. Finally "reach-ness" was basically just how far down the consensus draft board will teams go, do they always take the fallers (CAR), or always take guys not projected to go for another 10-15 picks. Also this kept the predictions somewhat normal. Obviously the NHL draft is incredibly random, and I think this model captured a good amount of randomness, but without taking into account "raech-ness" guys like LJ Mooney could have gone early in the first bc the scoring and nationality, but obviously that was never going to happen, so I needed something to stop that. Also, the consensus board was determined by an average of the rankings from my public scout analysis writeup (EP, Dobber, FC, Smaht, Pronman, Wheeler, Bob, Cosentino, McKeens, Button, DraftPros, and Ryan Kennedy).
It was also quite a simple model, basically all I did was look at what each team did in the draft over the past 5 seasons, then look at every avaiable player for that team to take at that pick, give them a distance score for each of the characteristics, then average those, then take the player with the smallest distance score*. At least that was the initial plan, and what I coded, but then I realized one major issue, the reach-ness score, which used draft pick values, helped to stop teams from making insane reaches, also stopped teams from picking "insane" fallers, because nobody ever picks a player projected to go top 3, 20th overall. So once a guy started falling, he wouldn't stop unless I stepped in. Which for the mock draft I posted on Twitter I did, I would usually just go abck a few picks and look at when the falling player had the highest percent chance of getting picked, and pick them there. Also I took the (inverted) average distance z scores and ran a softmax algorithm on them to turn them into probabilities. I did want to publish this as an interactive app like the PFF mock draft simulator, but I ran out of time, and would have to work out the kinks before doing that, but I hope to have it out by the 2026 NHL draft season.
Results
I posted the results of the prediction simulator on my twitter and got way more traction than I was ever expecting, so I figure that a lot of people have probably already seen this, but here it is anyway:
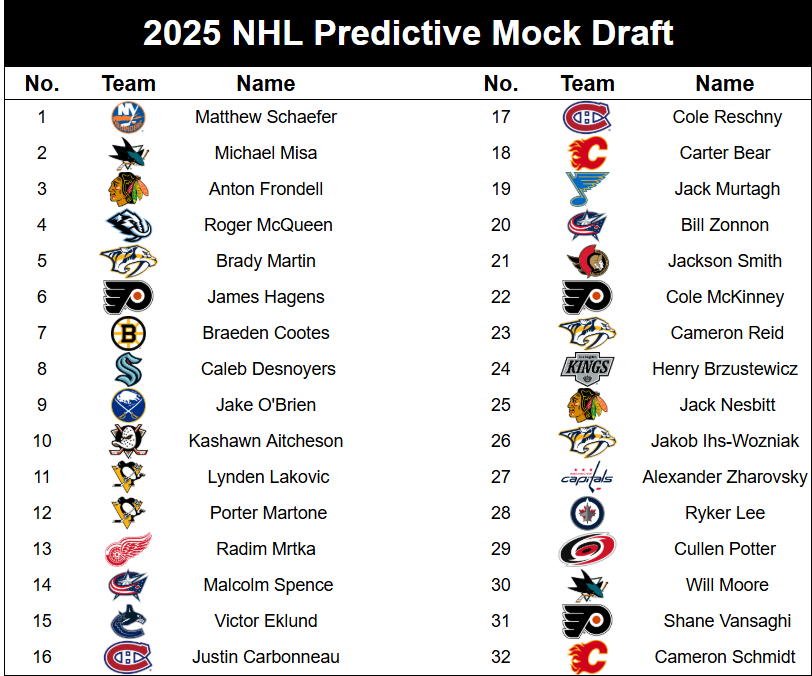
Looking back on this and comparing pick for pick, it obviously wasn't perfect, but most peoples predictions weren't. Getting the top 3 right was nice and an encouraging start. Martin to Nashville was a pretty easy pick if I recall, and Philly the model was almost perfectly split between Hagens and Martone, and I ended up going with Hagens for them when they got Martone, which I feel like messed up a few picks later as well. I'll take Jake O'Brein going one pick later as a W as well, even it it was to a different team. Then we got the pens picks, which were just terrible predictions, Lakovic, and Martone, when they ended up as Kindel who I predicted outside the first, and a trade for Nesbitt who I predicted 25th. Almost nailing the Eklund fall was also nice, I thought for sure VAN was going to take him on draft day too. Then obviously my model predicted 2 MTL picks because I ran it before the Dobson trade, so I don't really blame them for being off, though both guys went shortly after. It also predicted Brz to the kings, just at the wrong pick, and I'm happy Potter and Lee went around where it projected them as well. Now obviously the model was never going to take a goalie Rd 1 because teams do it so rarely, that every positional difference for Gs was very high. Also they don't score, so I think I just put like average middle of the draft scoring for them.
One other major issue with this system is how regiems and scouts change across the league. Sure, some teams are incredibly consistent with their GM and head scout, but others change somewhat frequently. For example, the 2025 penguins probably picked more like the 2020 Dubas+Wes Clarke leafs than the 2020 penguins, so that will always throw a wrench in predictive modelling by team. I debated rebuilding the model but with GMs instead of teams as the "grouping" factor, but they still rely on their scouts, who frequently change and I don't have data on which scouts were with which teams during certain seasons. Even if I did have that data, if I was looking at scouting "units" and how they tend to draft, I would have no data because they probably change so frequently. Though this just gave me an incredibly funny thought of running like an "RAPM" (ridge regression) model to determine scouts biases by looking at teams drafting habits before/after the scout. Which obviously would be entirely meaningless, tiny sample size randomness, but it would be kind of funny.
Data
All the points and size nationality and whatnot data came from eliteprospects. I also got the historical draft data from eliteprospects as well. Then looking at all of the rankings, I got them from the same sites as I did for my public rankings analysis. Either TSN/THW/Sportsnet, or the site itself, or EP rinkside/the EP draft guide for the EP rankings of course.